模型的记忆变理得加重要
 一、大模型的核心处理能力已具备实用价值
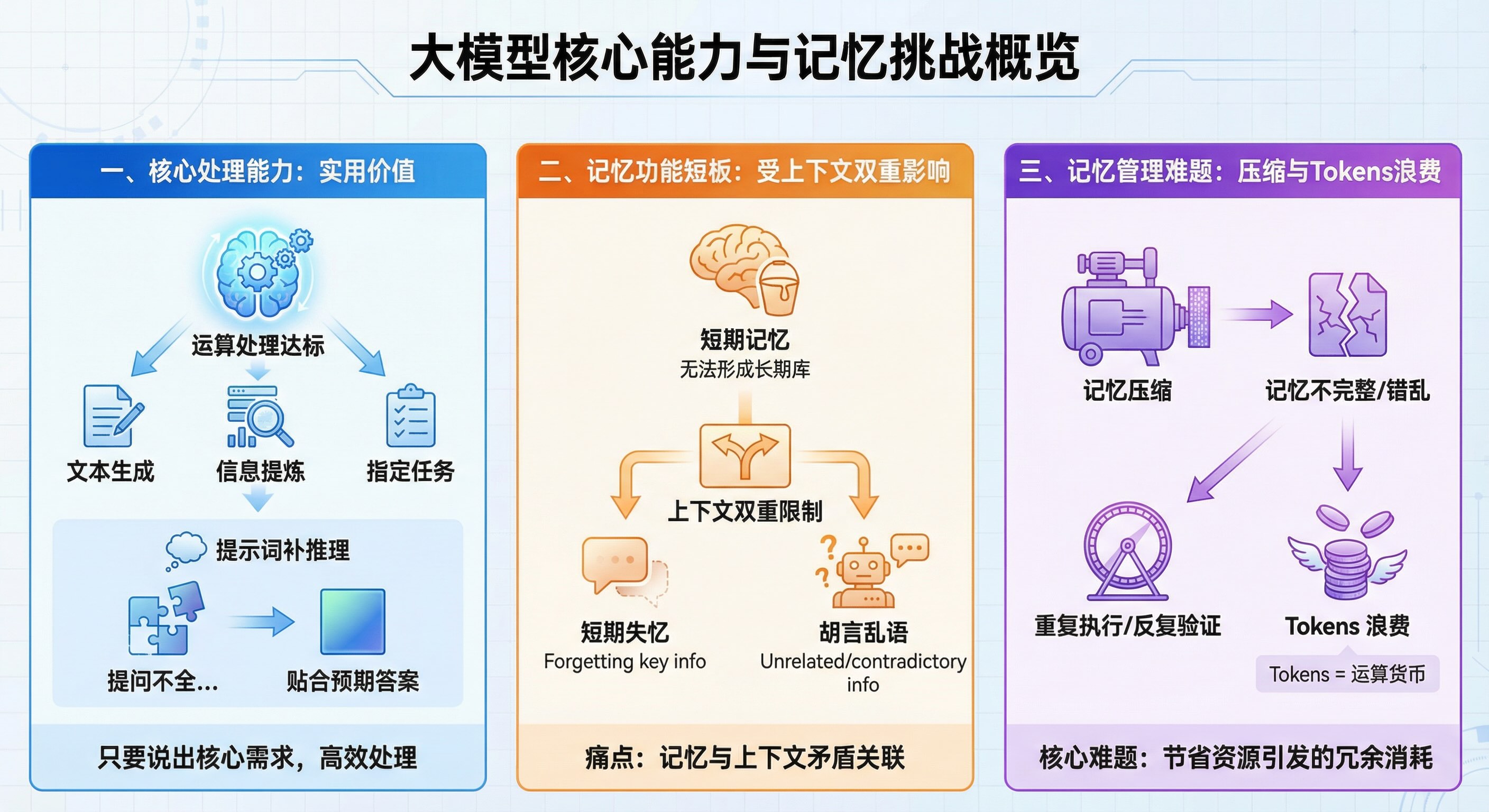
一、大模型的核心处理能力已具备实用价值
如今的大模型在核心处理任务上已经“够用”了。无论是文本生成、信息提炼,还是根据用户需求完成指定任务,它的运算和处理能力都达到了实际使用标准。尤其在“提示词补推理”方面表现亮眼——哪怕用户的提问不够完整、逻辑不够清晰,模型也能通过自身的推理能力,补全提示词中的隐含需求,给出贴合预期的答案。简单说,只要用户能把核心需求说出来,模型就能接住需求并高效处理。
二、记忆功能存在明显短板,受上下文双重影响
大模型目前最大的痛点是“记忆能力”不足,还没有成熟的解决方案。它的记忆受上下文严重限制:一方面,只能记住当前对话的短期信息,没法像人类一样形成长期稳定的记忆库;另一方面,这种记忆又和上下文存在“矛盾关联”——明明受限于上下文长度,很多时候却又会出现和上下文无关的记忆偏差,比如突然提及之前没聊过的内容,或是忘记刚讨论过的关键信息,就像“短期失忆又偶尔胡言乱语”。
三、记忆管理的核心难题:压缩与tokens浪费
如何科学管理大模型的记忆,是当前的关键难题。为了节省存储和运算资源,需要对记忆内容进行压缩,但哪怕是很小幅度的压缩,都可能引发问题:模型会因为记忆不完整或错乱,重复执行已经完成的任务,或是反复验证已知结论。这不仅会让回复变得冗余,还会浪费大量“tokens”——相当于模型处理任务时的“运算货币”,每一次重复和验证都会消耗tokens,造成不必要的资源浪费。
 鲁公网安备37010202700455号
鲁公网安备37010202700455号