claude最新模型的思考
 一、大厂优先测试:提前排查“隐藏风险”
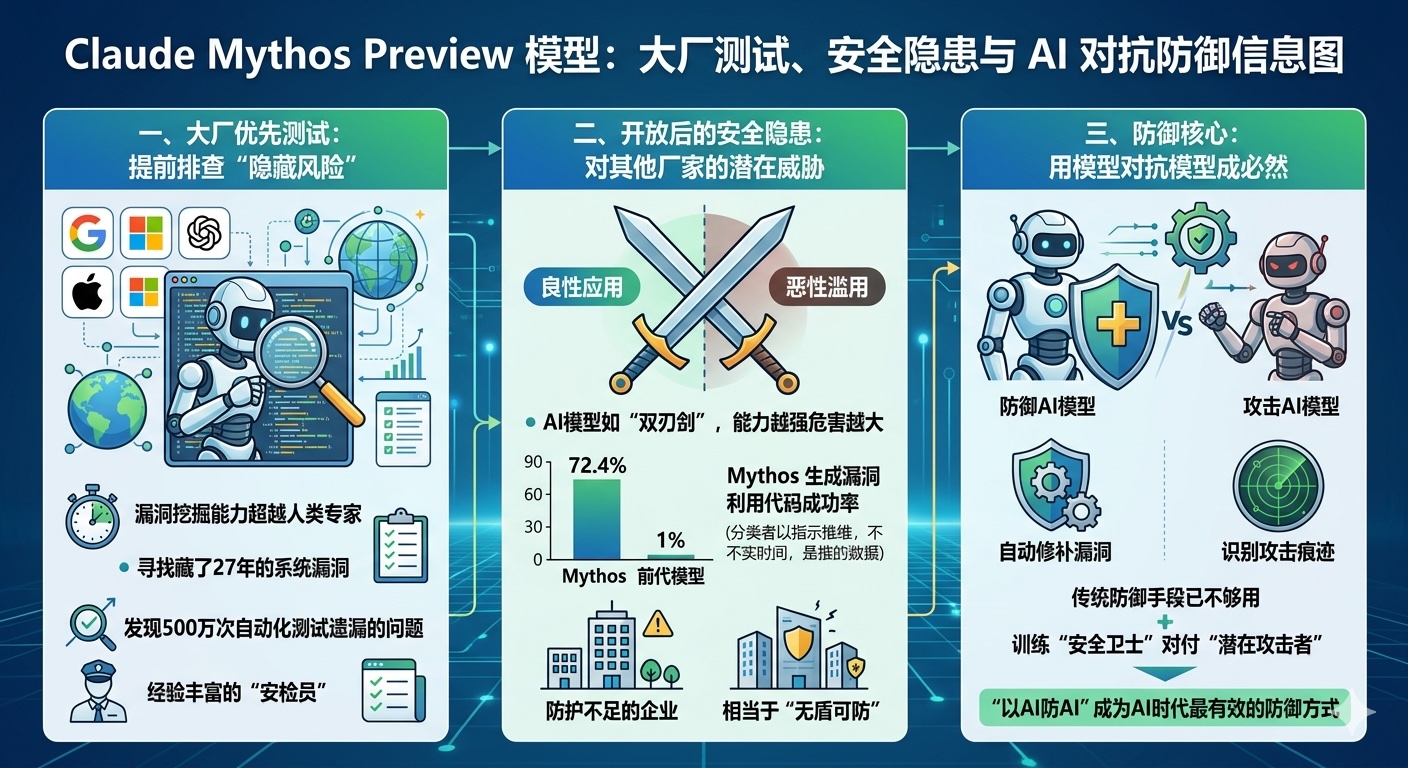
一、大厂优先测试:提前排查“隐藏风险”
Claude的最新预览版先开放给国外大厂,核心是做“漏洞提前筛查”。这款名为Mythos Preview的模型,漏洞挖掘能力已超越多数人类专家,能找到藏了27年的系统漏洞,甚至发现500万次自动化测试遗漏的问题。让技术实力强、应用场景复杂的大厂先用,就像让经验丰富的“安检员”提前试错,把模型可能存在的安全漏洞、使用风险找出来,避免后续大范围开放时出问题,是一种谨慎的“先内测再推广”思路。
二、开放后的安全隐患:对其他厂家的潜在威胁
这种“大厂先测”的行为,也暗示了模型开放后的安全风险。AI模型就像一把“双刃剑”,能力越强,被滥用的危害越大。比如之前有开源AI因漏洞导致敏感数据泄露,而Claude新模型生成漏洞利用代码的成功率高达72.4%,远超前代的1%。一旦这类能力被不法分子利用,可能攻击其他厂家的系统、窃取数据,对技术实力较弱、防护不足的企业来说,相当于“无盾可防”,自然存在安全隐患。
三、防御核心:用模型对抗模型成必然
面对AI带来的新风险,传统防御手段已经不够用了。就像用病毒查杀软件对付电脑病毒,未来防御AI攻击,也得靠更强大的AI模型。Claude新模型的测试案例证明,AI能精准找到系统漏洞,反过来,也能让AI提前识别攻击痕迹、修补漏洞、抵御恶意利用。这种“以AI防AI”的思路,就是用模型的能力对抗模型的风险,就像训练“安全卫士”专门对付“潜在攻击者”,成为AI时代最有效的防御方式。
 鲁公网安备37010202700455号
鲁公网安备37010202700455号